
Report
OceanGPT Technical Report
The ocean not only harbors immense—and still largely untapped—resources, but also represents a frontier that remains largely inaccessible and poorly understood by humankind. Advances in artificial intelligence (AI), particularly foundation models in natural language processing and computer vision, have delivered unprecedented capabilities in pattern recognition and predictive analytics.Currently, directly applying foundation models to the ocean domain presents numerous challenges, prompting researchers to explore how best to adapt and deploy these models for ocean AI applications.
First, effective oceanic AI demands deep domain expertise: the ocean is governed by a rich lattice of specialized concepts—from hydrographic processes to biogeochemical cycles—that general purpose models simply do not possess. Second, the ocean yields a distinctive suite of multimodal data (sonar echoes, optical imagery, electromagnetic readings, and more) that far exceed the sensory modalities most foundation models are built to process. Finally, many critical applications—especially those reaching into the deep sea—depend on robotic platforms, yet existing foundation models lack the capability to directly drive or coordinate underwater vehicles and sensors. Addressing these challenges will require foundation models that integrate domain knowledge, naturally ingest heterogeneous ocean data, and seamlessly interface with oceanic robotic systems.

OceanGPT-series and system architecture.
To address these challenges, we introduce the OceanGPT project. The development of OceanGPT began in 2023, when we released the first large language model, OceanGPT-basic, tailored for the ocean domain. Since then, we have continuously iterated and improved the model. In particular, we enhanced OceanGPT-basic with domain-specific knowledge through knowledge augmentation techniques, improving its capabilities in ocean domain-specific question answering. Building upon this foundation, we released a series of advanced versions, including a monolingual multimodal model, a bilingual multimodal model OceanGPT-o, and most recently, OceanGPT-coder — a code-oriented large language model designed to support underwater robot control.
OceanGPT can be applied to various scenarios such as ocean domain question answering, multimodal understanding of oceanographic data, underwater robot control, and embodied intelligence in underwater environments. It can support a wide range of ocean applications, including underwater archaeology, seabed exploration, oceanographic research, and submarine cable and pipeline monitoring. Below, we introduce the technical details.
OceanGPT-basic
In the early stages, we collected open-access ocean domain papers and related data from the Web. We performed continuous pre-training on this data after applying rule-based filtering, length filtering, and deduplication. However, we later found that directly training the model in this way did not lead to a solid grasp of domain knowledge.
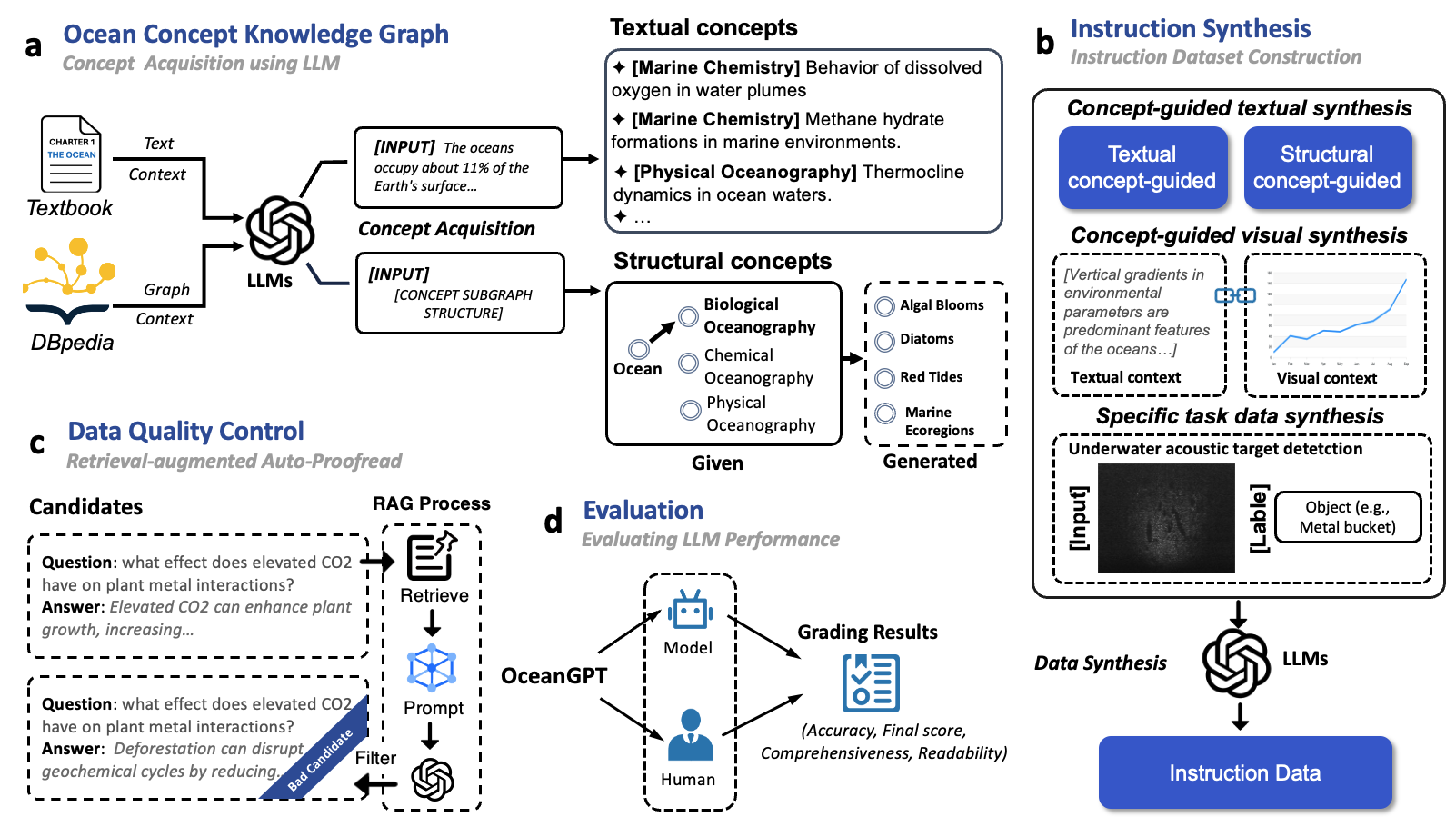
Knowledge-augmented instruction data generation for OceanGPT
To address this, we extracted conceptual knowledge from publicly available ocean literature and constructed a knowledge graph, primarily with the help of general-purpose large language models. We then used this knowledge graph to synthesize domain-specific instruction data in the ocean field (as illustrated). Additionally, we adopted a retrieval-augmented generation (RAG) approach to further enrich the instruction data. To enhance multilingual support, we used large language models to translate the instructions into multiple languages. We observed that the resulting instruction data was of high quality and demonstrated strong domain relevance in the ocean domain. A portion of this data was also used to train OceanGPT-o.
After data collection, we trained the model based on the Qwen. Meanwhile, we built a domain-specific knowledge base using expert-curated ocean data for RAG. The model automatically determines whether retrieval is needed, and if so, queries the knowledge base to enhance its responses. In our online system, we employ a hybrid architecture that integrates general and domain-specific capabilities by calling DeepSeek, enabling a seamless fusion of general-purpose knowledge and ocean expertise.
OceanGPT-o
We collected a large amount of publicly available sonar data from the internet, and additionally acquired a substantial set of real-world sonar data using an ROV in the coastal waters near Zhoushan, Zhejiang Province. Based on these sonar images and corresponding target labels, we synthesized multimodal instruction data using large language models.
Furthermore, we crawled ocean-related images and descriptions from publicly available research papers online. Using these resources, we manually and automatically generated relevant questions and answers with the help of large language models, constructing additional multimodal instruction data. We then applied rule-based filtering to clean and refine the dataset.
After data collection and preprocessing, we used the cleaned dataset to train our model, primarily based on Qwen. The trained model can take sonar images or ocean science-related images as input and generate textual interpretations. However, due to the limited diversity of target types in our sonar dataset, the model may struggle to recognize previously unseen sonar images. In addition, hallucination in model-generated outputs remains a potential issue.
OceanGPT-coder
We trained OceanGPT-coder based on Qwen using our proprietary code instruction data. The instructions were constructed through a combination of manual design and large language model generation, and each instruction includes an input, the model’s reasoning process, and the resulting output code.
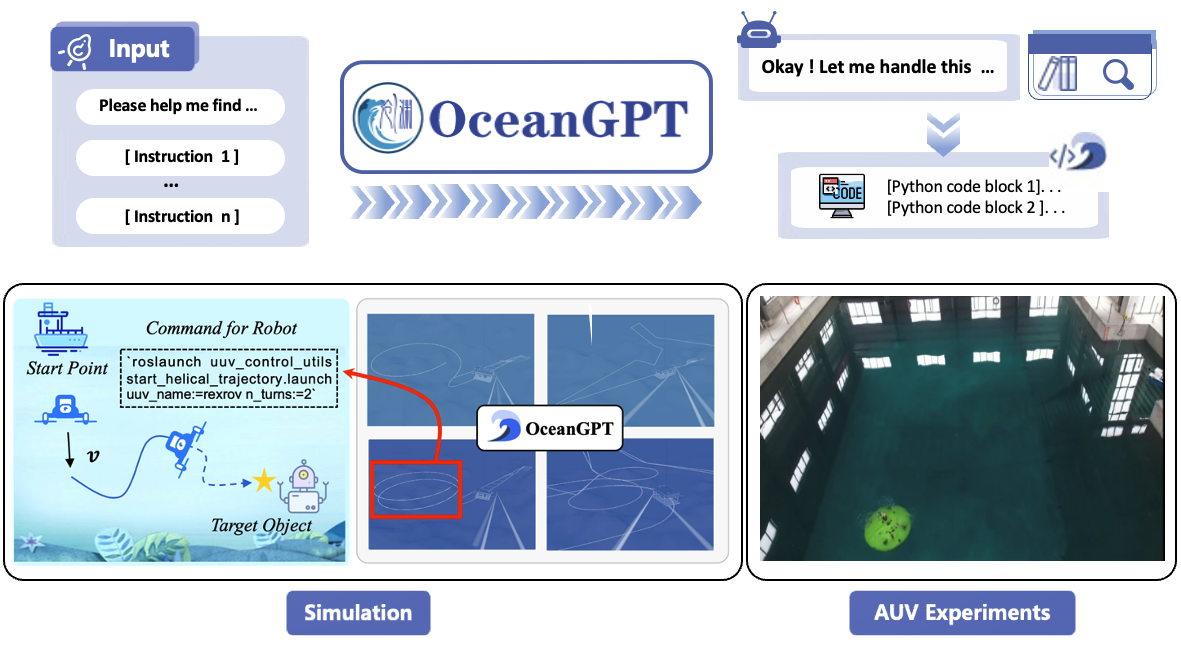
OceanGPT-coder for underwater embodied intelligence
The generated code can be directly embedded into simulators and real underwater robots to perform tasks. OceanGPT-coder has already successfully generated MOOS code that was technically validated on Zhejiang University’s HY2 AUH. Currently, the model only supports MOOS code generation, but we plan to extend its capabilities to support code generation for additional platforms in the future.
Conclusion
Ocean data is rich in unique characteristics, offering immense potential for advancing domain-specific intelligence. To fully harness this potential, we believe that new models tailored to the complexities of the ocean are essential. By combining the power of human insight with cutting-edge AI techniques, we aim to build machine intelligence that truly understands the ocean.
Limitations
The model may have hallucination issues.
Due to limited computational resources, OceanGPT-o currently only supports natural language generation for certain types of sonar images and ocean science images. OceanGPT-coder currently only supports MOOS code generation.
We did not optimize the identity and the model may generate identity information similar to that of Qwen/MiniCPM/LLaMA/GPT series models.
The model’s output is influenced by prompt tokens, which may result in inconsistent results across multiple attempts.