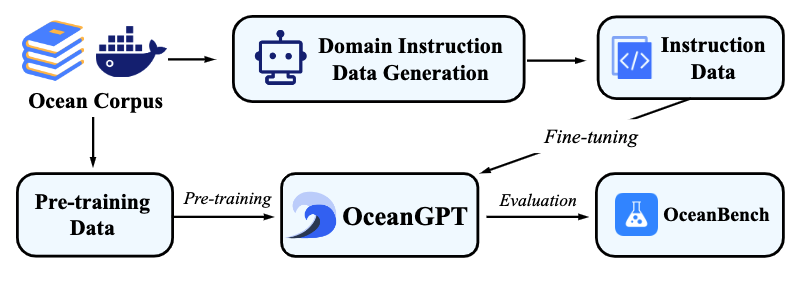
Data quality is crucial for training domain large language models. To train OceanGPT, we collected an ocean science corpus spanning multiple fields. Each subfield and topic has its unique data characteristics and patterns, leading us to propose a domain-specific instruction generation framework named DoInstruct. This framework utilizes multi-agent collaboration to generate fine-tuning training data for ocean science instructions. This approach ensures both the professionalism and accuracy of the data while achieving efficient parallel data generation performance. The DoInstruct framework employs agents (such as GPT-3.5-turbo) as experts for each ocean topic, with each agent rapidly expanding instructions through mutual collaboration. The framework defines three agent